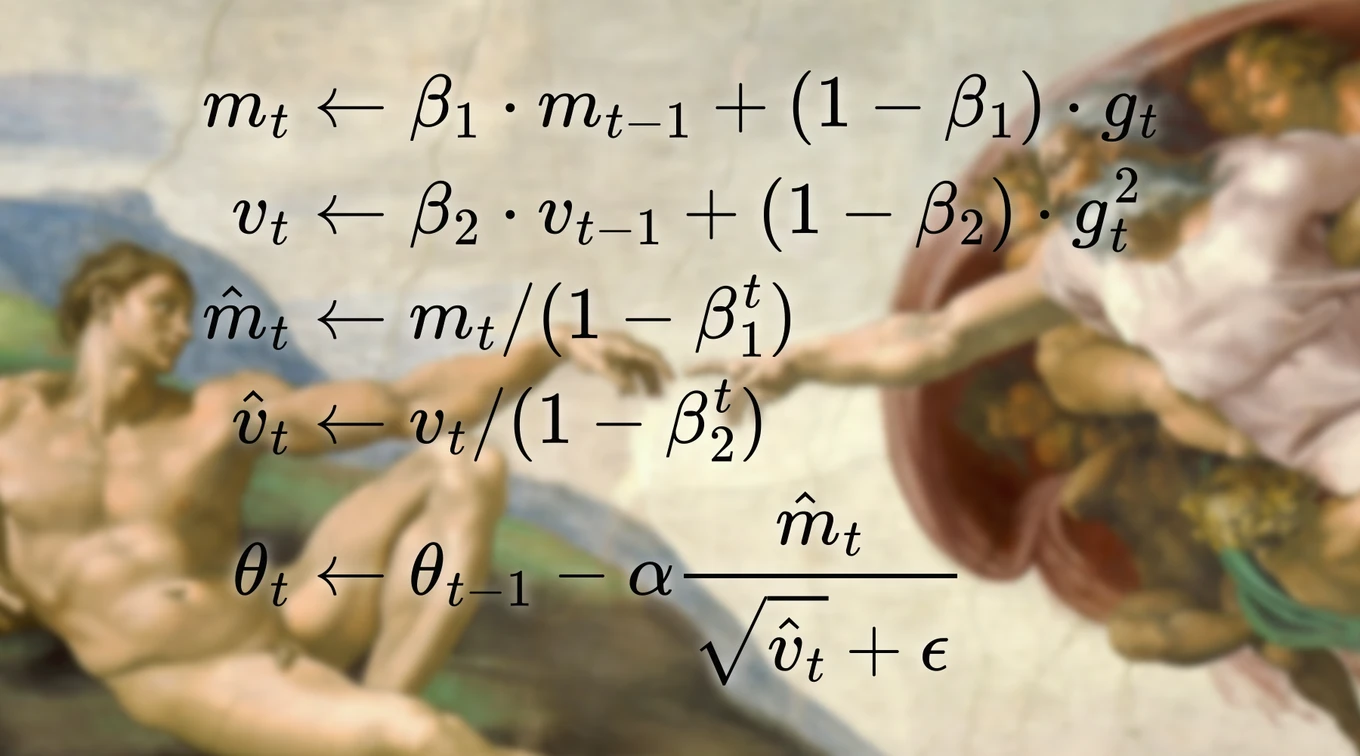I wrote this post because I was frustrated to find no convincing theoretical explanation of the success of the Adam optimizer (Kingma, 2014). More precisely, Adam is the RMSprop optimizer (Hinton, 2012) + momentum. While understanding momentum is quite simple as a way to deal with a badly conditioned loss landscape, the RMSProp update rule is often unintuitive when coming from the world of quadratic optimization; in particular, the square root in the denominator is quite intriguing. Fortunately, I stumbled on an article that gave a somewhat satisfying answer (Aitchison, 2020). However, I found the derivation somewhat convoluted, particularly the introduction of Ornstein–Uhlenbeck dynamics. In this article, I describe a Bayesian derivation of the RMSProp update rule, close to the one proposed in the mentioned article, but conceptually simpler.
The derivation uses the framework of Bayesian estimation/filtering, unlike other more common geometric approaches.
Let's begin! We will first demonstrate how SGD (Stochastic Gradient Descent) can be derived from Bayesian principles and then show how Adam refines it.
Bayesian derivation
Maximum likelihood principle
Usually, we train models using the maximum likelihood principle: we want to find the most likely parameters θ∗ of our model given the observation of our dataset D. More formally, we are searching:
θ∗=argθmaxp(θ∣D)
Bayes theorem is usually used here to get:
p(θ∣D)=p(D)p(D∣θ)p(θ)
And using the log likelihood instead of the likelihood, we get:
This motivates the use of the loss function as an optimization objective with regularization of the weights (e.g., weight decay) to model the evidence and prior terms, respectively. The analysis generally proceeds by introducing an optimizer to find the best parameters using geometric arguments. It then explains the difficulty of obtaining the true gradient and introduces Stochastic Gradient Descent (SGD) as a solution to this issue.
Going further to discover SGD
In this section, we further apply Bayesian methods to gain deeper insight into the problem.
In practice, the model sees dataset samples sequentially. At each step, we present the model only a subset B of the dataset (a "batch"). Suppose we are already at some step t of our training and we have an estimate θt of θ∗. We have a new batch B, and we want to update our estimate using the information it contains. As before, we can express this problem as a maximum likelihood estimation problem. However, this time we will not assume we know the whole dataset, only the previous parameter estimate and the new batch:
θ∗=argθmaxp(θ∣B,θt)
We can use the Bayes theorem here too:
p(θ∣B,θt)=p(B∣θt)p(B∣θ)p(θ∣θt)
Taking the log likelihood and getting rid of constant (wrt θ) terms, we get:
new belieflogp(θ∣B,θt)⌣new evidencelogp(B∣θ)+past belieflogp(θ∣θt)
Now, if we decide to model the term p(θ∣θt) by a normal distribution N(θt,σ2I) with a variance σ2 chosen to represent our uncertainty about the value of θ∗ prior to observing B, we get:
logp(θ∣B,θt)⌣logp(B∣θ)−2σ21∥θ−θt∥2
The second term forces the optimal value to be relatively close to θt. We can thus use a linear approximation for the loss function L(θ)=−logp(B∣θ) near θt, the problem becomes the following minimization problem:
This is the stochastic gradient descent algorithm. This derivation shows that the SGD algorithm can be understood and derived using Bayesian principles. The learning rate represents the variance in our belief of the "optimal parameters". As a bonus, within this framework, decaying learning rate scheduling has a clear interpretation as an increase in confidence in the estimate of the best parameters as training progresses. A learning rate decreasing like 1/t would match the Cramer-Rao bound convergence rate.
Going even further to discover RMSProp
The question is, can we derive other popular optimization algorithms from this framework? In particular, can we estimate σ2 instead of guessing its value?
In our derivation of SGD, we used a linear approximation for L(θ)=−logp(B∣θ). We will see that we can actually do better using a quadratic approximation. Indeed, the Taylor expansion theorem states that we can do the following approximation:
However, even in this form, the approximation is not usable because the matrix is generally too big. But if we suppose that the gradients are approximately centered and uncorrelated, off-diagonal terms vanish, and we can estimate G as a diagonal matrix:
diag(E[g12],…,E[gd2])≈G
the algorithm can now be decomposed component wise by denoting s the estimated vector containing the diagonal element of G obtained by an exponential moving average and σ the diagonal of Σ:
stσtθt=βst−1+(1−β)g2=(st+σt−1−1)−1+η2=θt−1−σtgupdate of the moving average of square gradientsupdate of the covariance of the belief distributionupdate of the mean of the belief distribution
Linking the new optimizer to Adam
You may not recognise its proximity to the RMSProp update rule. Let's push the analysis a bit further to see how it is connected.
To see to what value the covariance matrix converges, we can search for a fixed point verifying:
Σ=(G+Σ−1)−1+η2I
In our simplified optimizer, we replaced G by s and Σ by σ, and all the operations are element-wise. We can solve this equation easily using scalar arithmetics:
This a second order polynomial in σ2 let's compute the determinant:
△=η4s2+4sη2=η2s(η2s+4)
And the unique positive solution:
σ2=2sη2s+η2s(η2s+4)=2η2+ηsη2s/4+1
We can also get a similar result without supposing G & Σ diagonal using the full matrices. For completeness, you can find the demonstration here, even if the resulting algorithm is probably impractical.
We search Σ such that:
ΣΣ(G+Σ−1)Σ2=(G+Σ−1)−1+η2I=I+η2(G+Σ−1)−1=η2(Σ+G−1)multiplying byΣon the left &G−1on the right
Note that we supposed that G is invertible. Now substituting Σ2 by ((Σ−2η2I)+2η2I)2 (inspired by canoniocal form of 2nd order polynomial) we get:
When η is small enough (our quadratic approximation is good), we can neglect
the term η2s/4 before 1 leading to the following approximation:
σ2≈2η2+ηs1
Again, when η is small, we can neglect the first term. Finally, we get:
σ2≈ηs1
Plugging this into our parameter update rule, we get the following approximation of the Bayesian optimizer described before:
stθt=βst−1+(1−β)g2=θt−1−ηstgupdate of the moving average of square gradientsupdate of the mean of the belief distribution
This is the RMSProp optimizer update. It has a benefit over the full Bayesian optimizer: it needs one less statistic to be stored, reducing memory usage.
Choosing η
The parameter η is introduced to account for the fact that we are using approximations which reduce our confidence in the estimates. It's interesting to study the optimizer in different regimes.
Large η
When η is large (i.e., we have little confidence in our approximation) and η2s/4≫1, we can make the following approximation:
σ2=2η2+ηsη2s/4+1≈2η2+ηsη2s/4=2η2+2η2=η2
and the update rule is:
θt=θt−1−η2g
This is the SGD algorithm. Thus, both RMSProp and SGD can be seen as approximations of two different regimes of a general Bayesian optimizer.
Small η
We already supposed that η is small, but what happens when η→0? In this case, the fixed point also converges to zero, and we cannot use this approach directly. Instead, we can use the full update step, which approximates to
Interestingly, this leads exactly to the well-known natural gradient descent algorithm with a learning rate that decreases as 1/t. It is a bit like an "online" natural gradient optimizer. For reference, the update rule is the same, except that t usually represents the total number of samples in the dataset. The variance decreases as 1/tG−1, which is expected as we gather a datapoint at a time, our estimator matches the convergence rate of the Cramer-Rao bound.
Conclusion
In this article, I provided a hopefully more compelling explanation for the success of the Adam optimizer in deep learning compared with regret-based approaches. It changes the interpretation of RMSProp from an "optimization" algorithm searching for a good solution through a loss landscape to a "learning procedure" that incorporates information efficiently by updating a belief using the Bayes rule. From this perspective, Adam is probably close to optimal as a quadratic extension of SGD.